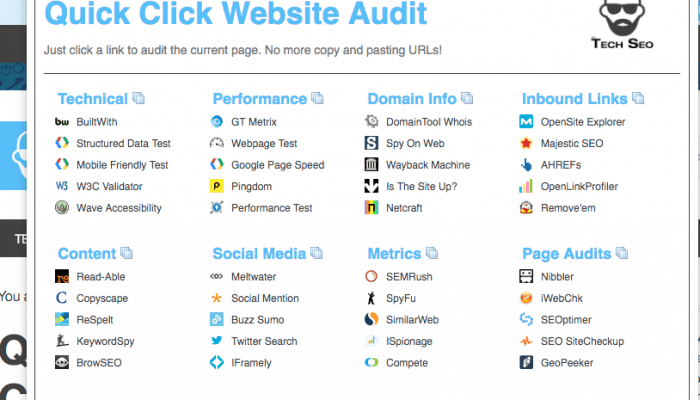
The internet is full of free and freemium SEO audit tools. I have a bookmark bar full of links to tools to look at the technical, content, and off-site metrics for a page. When I audit a page or a website, I am constantly copying and pasting URLs into these tools to get that audit data. This can be … Download the extension here.
Featured Article

How Technical SEO Procrastination Hurts Your Redesign Effort
Throughout my career, I’ve worked on web design, development, and marketing teams and have touched almost every aspect of a website relaunch. Today, as an SEO, I see … Read This Article
More Apps
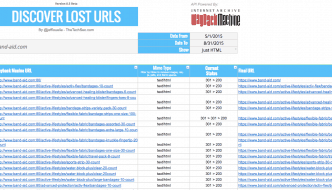
Discover Lost URLs with Wayback Machine’s API
After reading Patrick Stox's post on Search Engine Land about Fixing Historical Redirects, I was inspired to start using Wayback Machine's API within … Check Out This App.